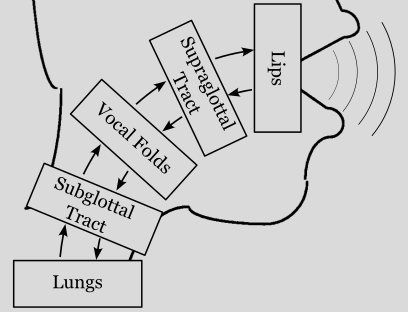
Synthesis Basics#
The top-level module letalker directly houses all the commonly used
features of pyLeTalker that are essential to run the voice synthesis while more
advanced features remain only in their respective submodules. The following
lists summarize all the top-level functions and classes.
Sampling rate and time vector
Simulation Functions
Run simulation
Run simulation with kinematic vocal fold model
Synthesis Elements
Vocal Folds classes
Self-oscillating 3-mass model (Titze and Story, 2002)
Kinematic vocal fold model (Titze 1984)
Vocal source model with known glottal flow function
Vocal fold model with known glottal area waveform
Vocal Tract classes
Wave-reflection vocal tract model (Liljencrants, 1985; Story, 1995)
Lossy Straight Tube Vocal Tract model
Lungs class
Constant-pressure lung model with impedance matching
Constant-pressure lung model with zero-reflection
Zero-pressure lung model, only reflecting 80% of the backward pressure
Lips class
Ishizaka-Flanagan
Function Generators
There are three types of generators to produce parameter samples.
Standalone Generators
Constant function generator
Step function generator
Line generator
Periodic interpolator
Clamped interpolator
Generates quasi-random sum of sinusoids (generalization of Klatt & Klatt, 1990)
Sine wave generator (analytic)
Modulated sine wave generator (analytic)
Rosenberg's pulse trains (Rosenberg, 1971)
Function Modifiers
Combines function generator outputs by multiplication
Combine function generator outputs by summation
Generates exponential function generator wrapper
Log function generator
Random Noise Generators
White noise generator
Colored noise generator
Sampling Rate and Time Vector#
- letalker.fs#
System-wide sampling rate in samples per second. Default rate is 44100 S/s
- letalker.ts(nb_samples, n0=0)#
Return time vector in seconds.
Parameters#
- nb_samples
Number of samples
- n0, optional
Starting time sample index, by default 0
- sample_edges, optional
True to return time stamps associated with the edges of the samples, by default False
- upsample_factor, optional
Specify a positive integer to increase the sampling rate of the returned time vector, by default 0
Simulation Functions#
- letalker.sim(nb_samples, vocalfolds, vocaltract, trachea=None, lungs=None, lips=None, aspiration_noise=None, *, return_results=True, n0=0)#
Run simulation
Parameters#
- nb_samples
Number of samples to generate
- vocalfolds
Vocal fold model
- vocaltract
Supraglottal vocal tract. If a 2-letter vowel name (e.g.,
'aa'&'ii') is passed, the defaultLeTalkerVocalTractmodel will be used with a male vocal tract, configured to the specified vowel. If 1D or 2D array or aFunctionGeneratorobject is passed, it will be used as the cross-sectional areas (in cm²) of vocal tract sections (if 2D, the first dimension is the time axes). To specify other parameters of theLeTalkerVocalTract, you may pass in a dict of key-value pairs. A customVocalTractmodel object could also be passed.- trachea, optional
Subglottal vocal tract model, by default None to use the
LeTalkerVocalTractmodel with the default trachea cross-sectional areas ('trach'). If 1D or 2D array or aFunctionGeneratorobject is passed, it will be used as the cross-sectional areas (in cm²) of vocal tract sections (if 2D, the first dimension is the time axes). To specify other parameters of theLeTalkerVocalTract, you may pass in a dict of key-value pairs. A customVocalTractmodel object could also be passed.- lungs, optional
Lungs model, by default None to use
LeTalkerLungsmodel with the default 7840 dyn/cm² lung pressure level (with the onset time of 2 ms). A float value changes the pressure level while a FunctionGenerator object can be specified to alter the temporal profile. A customLungsmodel object could also be passed.- lips, optional
Lips model, by default None to use
LeTalkerLipsmodel (Ishizaka-Flanagan lips radiation model). A customLipsmodel object could also be passed.- aspiration_noise, optional
Aspiration noise model, by default None to disable aspiration noise injection (or keep the default aspiration noise mode of the specified
VocalFoldsmodel). Passing inTrueenables the injection model (LeTalkerAspirationNoise) at the default level and threshold. Use a key-value dict to customize LeTalkerAspirationNoise further or pass in a customAspirationNoisemodel object.- return_results, optional
If
True, also return the results dict of all the simulation elements, by default True- n0, optional
Simulation starting time in sample index, by default 0
Returns#
- poutNDArray
Radiated acoustic pressure signal
- resultsdict[SIM_RESULTS_KEY, Element.Results], optional
The parameters and results of the simulation elements
- Parameters:
nb_samples (int)
vocalfolds (VocalFolds)
vocaltract (str | ArrayLike | FunctionGenerator | dict | VocalTract)
trachea (ArrayLike | FunctionGenerator | dict | VocalTract | None)
lungs (float | FunctionGenerator | Lungs | None)
lips (Lips | None)
return_results (bool)
n0 (int)
- Return type:
NDArray | tuple[NDArray, SimResultsDict]
- letalker.sim_kinematic(nb_samples, xi_ref, vocaltract, trachea=None, lungs=None, lips=None, aspiration_noise=None, *, return_results=True, n0=0, **kvf_kws)#
Run simulation with kinematic vocal fold model
Parameters#
- nb_samples
Number of samples to generate
- xi_ref
reference vocal fold motion (periodicity/qusiperiodicity required to )
- L0
relaxed vocal fold length in cm
- T0
relaxed vocal fold thickness in cm
- fo2L
fo-to-length conversion, or 2 coefficients of Titze-Riede-Mau conversion
- xim
vibration maximum amplitude in cm
- vocaltract
Supraglottal vocal tract. If a 2-letter vowel name (e.g., ‘aa’ & ‘ii’) is passed, the default
LeTalkerVocalTractmodel will be used with a male vocal tract, configured to the specified vowel. If 1D or 2D array or aFunctionGeneratorobject is passed, it will be used as the cross-sectional areas (in cm²) of vocal tract sections (if 2D, the first dimension is the time axes). To specify other parameters of theLeTalkerVocalTract, you may pass in a dict of key-value pairs. A customVocalTractmodel object could also be passed.- trachea, optional
Subglottal vocal tract model, by default None to use the
LeTalkerVocalTractmodel with the default trachea cross-sectional areas ('trach'). If 1D or 2D array or aFunctionGeneratorobject is passed, it will be used as the cross-sectional areas (in cm²) of vocal tract sections (if 2D, the first dimension is the time axes). To specify other parameters of theLeTalkerVocalTract, you may pass in a dict of key-value pairs. A customVocalTractmodel object could also be passed.- lungs, optional
Lungs model, by default None to use
LeTalkerLungsmodel with the default 7840 dyn/cm² lung pressure level (with the onset time of 2 ms). A float value changes the pressure level while a FunctionGenerator object can be specified to alter the temporal profile. A customLungsmodel object could also be passed.- lips, optional
Lips model, by default None to use
LeTalkerLipsmodel (Ishizaka-Flanagan lips radiation model). A customLipsmodel object could also be passed.- aspiration_noise, optional
Aspiration noise model, by default None to disable aspiration noise injection (or keep the default aspiration noise mode of the specified
VocalFoldsmodel). Passing inTrueenables the injection model (LeTalkerAspirationNoise) at the default level and threshold. Use a key-value dict to customize LeTalkerAspirationNoise further or pass in a customAspirationNoisemodel object.- return_results, optional
If
True, also return the results dict of all the simulation elements, by default True- n0, optional
Simulation starting time in sample index, by default 0
Returns#
- poutNDArray
Radiated acoustic pressure signal
- resultsdict[SIM_RESULTS_KEY, Element.Results], optional
The parameters and results of the simulation elements
- Parameters:
nb_samples (int)
xi_ref (float | AnalyticFunctionGenerator)
vocaltract (str | ArrayLike | FunctionGenerator | dict | VocalTract)
trachea (ArrayLike | FunctionGenerator | dict | VocalTract | None)
lungs (float | FunctionGenerator | Lungs | None)
lips (Lips | None)
return_results (bool)
n0 (int)
- Return type:
NDArray | tuple[NDArray, SimResultsDict]
Synthesis Elements#
There are 4 voice production element types:
Vocal Folds (Glottis)
Vocal Tract (for both subglottal and supraglottal elements)
Lungs
Lips
pyleTalker provides at least one built-in class for each type.
Also, an aspiration noise model can be assigned to a vocal folds class to inject turbulent aspiration noise which is a function of the glottal flow.
Vocal Folds classes#
- class letalker.LeTalkerVocalFolds(*, act=None, ata=None, alc=None, x0=None, Lo=None, To=None, Dmo=None, Dlo=None, Dco=None, zeta=None, upstream=None, downstream=None, aspiration_noise=None)#
LeTalker 3-mass vocal fold model with muscle activity inputs
- Parameters:
act (SampleGenerator) – cricothyroid activity, can range from 0 to 1, defaults to 0.25
ata (SampleGenerator) – thyroarytenoid activity, can range from 0 to 1, defaults to 0.25
alf – lca activity, defaults to 0.5
x0 (SampleGenerator) – prephonatory displacement (lower, upper)
Lo (float) – vocal fold length at rest
To (float) – vocal fold thickness at rest
zeta (NDArray) – damping ratios [lower, upper, body], defaults to np.array([0.1, 0.6, 0.1])
upstream (VocalTract | float | None) – connected subglottal tract, defaults to None
downstream (VocalTract | float | None) – connected supraglottal tract, defaults to None
aspiration_noise (bool | dict | AspirationNoise | None) – True to use aspiration noise model, defaults to None
alc (SampleGenerator)
Dmo (float)
Dlo (float)
Dco (float)
- class Results(element: 'Element', n0: 'int', nb_samples: 'int', y: 'NDArray', ag: 'NDArray', ug: 'NDArray', psg: 'NDArray', peplx: 'NDArray', x: 'NDArray', f: 'NDArray', aspiration_noise: 'Element.Results | None')#
- class letalker.KinematicVocalFolds(fo_or_xi_ref, L0=None, T0=None, xim=None, fo2L=None, *, upstream=None, downstream=None, aspiration_noise=None, Ny=21, Nz=15, **kwargs)#
_summary_
Parameters#
- upstream, optional
subglottal tract object or subglottal cross-sectional area, by default None (open space with inf area)
- downstream, optional
epiglottal tract object or epiglottal cross-sectional area, by default None (open space with inf area)
- aspiration_noise, optional
True to use the default aspiration noise model (
LeTalkerAspirationNoise), a dict to use the default model with specific parameters, False or None to disable noise injection, or specify an existing AspirationNoise object, by default None (no noise injection)
- class Results(element, n0, nb_samples, ug, psg, peplx, aspiration_noise)#
Simulation Results
- Parameters:
- property displacements: NDArray#
maximum lateral displacements at the minimum opening along the depth
- property fo: NDArray#
fundamental frequency of the referenc VF motion in Hz
- property phi: FunctionGenerator#
phase of the referenc VF motion in radians
- Parameters:
fo_or_xi_ref (float | ArrayLike | AnalyticFunctionGenerator)
L0 (float)
T0 (float)
xim (SampleGenerator)
upstream (VocalTract | float | None)
downstream (VocalTract | float | None)
Ny (int)
Nz (int)
- class letalker.VocalFoldsUg(ug, *, length=None, upstream=None, downstream=None, aspiration_noise=None)#
_summary_
Parameters#
- upstream, optional
subglottal tract object or subglottal cross-sectional area, by default None (open space with inf area)
- downstream, optional
epiglottal tract object or epiglottal cross-sectional area, by default None (open space with inf area)
- aspiration_noise, optional
True to use the default aspiration noise model (
LeTalkerAspirationNoise), a dict to use the default model with specific parameters, False or None to disable noise injection, or specify an existing AspirationNoise object, by default None (no noise injection)
- Parameters:
ug (ArrayLike | SampleGenerator)
length (float | NDArray | SampleGenerator | None)
upstream (VocalTract | float | None)
downstream (VocalTract | float | None)
- class letalker.VocalFoldsAg(ag, *, upstream=None, downstream=None, length=None, aspiration_noise=None)#
Vocal fold model with known glottal area waveform
Parameters#
- ag
glottal area samples/generator. If an array, it will be converted to a
ClampedInterpolatorobject at the simulation sampling rate. If a callable, it is expected to take the form:ag(n:int, n0:int) -> NDArray
where n is the number of samples to generate at the simulation sampling rate and n0 is the time index of the first sample.
- As, optional
subglottal tract cross-sectional area, by default inf
- Ae, optional
epiglottal tract cross-sectional area, by default inf
- length, optional
vocal fold length, only required to use an aspiration noise model which needs the vocal fold length
- aspiration_noise, optional
True or dict value to enable the default bandpass noise model (dict input sets the aspiration noise model keyword arguments) or an
AspirationNoiseobject.
References#
- [1] I. R. Titze, “Parameterization of the glottal area, glottal flow, and vocal fold contact area,”
Acoust. Soc. Am., vol. 75, no. 2, pp. 570–580, 1984, doi: 10.1121/1.390530.
- Parameters:
ag (ArrayLike | Callable | SampleGenerator)
upstream (VocalTract | float | None)
downstream (VocalTract | float | None)
length (float | ArrayLike | SampleGenerator | None)
Vocal Tract classes#
- class letalker.LeTalkerVocalTract(areas, atten=None, log_sections=False, min_areas=None)#
Wave-reflection vocal tract model
- Parameters:
areas (ArrayLike | TwoLetterVowelLiteral | SampleGenerator) – cross-sectional areas of vocal tract segments
atten (float | None) – per-section attenuation factor, defaults to None
log_sections (bool) –
Trueto log the incidental pressure at every vocal tract segment, defaults to Falsemin_areas (float | None) – minimum allowable cross-sectional area to enforce positive area, defaults to None
- class letalker.LossyCylinderVocalTract(desired_length, area, atten=None)#
Ideal damped cylindrical vocal tract model
Parameters#
- desired_length
Desired total tube length in cm. The actual length is rounded to the nearest integer multiple of sound propagation distance per time sample interval.
- area
cross-sectional area in cm²
- atten, optional
loss factor per half unit length, by default None
- Parameters:
desired_length (float)
area (float | ArrayLike | SampleGenerator)
atten (float | None)
Lungs classes#
- class letalker.LeTalkerLungs(lung_pressure=None)#
Parameters#
- lung_pressure, optional
respiratory driving pressure from lungs (dyn/cm²), by default None to use the default value
lt.constants.PL
- class Results(element: 'Element', n0: 'int', nb_samples: 'int', plung: 'NDArray')#
-
- property ts: NDArray#
time vector
- create_result(runner, *extra_items, n0=0)#
Returns simulation result object
- create_runner(n, n0=0, s_in=None, **kwargs)#
instantiate a vocal folds element runner
(overloading abc.Element to account for the aspiration noise sub-element)
Parameters#
- n
number of samples to synthesize
- n0, optional
starting time index, by default 0
- s_in, optional
initial states, by default None
Returns#
simulation runner object
- generate_sim_params(n, n0=0, **_)#
parameters: - lung_pressure: lung pressure
- link(dst)#
set the upstream vocal tract object
Parameters#
- dst
downstream vocal tract
- Parameters:
dst (VocalTract)
- static modify_global_constants(fs=None, c=None, rho=None, mu=None)#
Modify the system constants (use None to keep existing)
Parameters#
- fs
time sampling rate in S/s (samples/second)
- c, optional
speed of sound in cm/s, by default None
- rho, optional
air density in g/cm³ (= kg/mm³), by default None
- mu, optional
air viscosity in dyne-s/cm² (= Pa·s = kg/(m·s)), by default None
- classmethod set_fs(new_fs)#
set class-wide sampling rate.
- Parameters:
new_fs (int | None) – sampling rate in samples/second. If None, it reverts the sampling rate to the default (44.1 kHz).
- static ts(nb_samples, n0=0, sample_edges=False, upsample_factor=0)#
Return time vector in seconds.
Parameters#
- nb_samples
Number of samples
- n0, optional
Starting time sample index, by default 0
- sample_edges, optional
True to return time stamps associated with the edges of the samples, by default False
- upsample_factor, optional
Specify a positive integer to increase the sampling rate of the returned time vector, by default 0
- unlink()#
disconnect the upstream vocal tract object
- Parameters:
lung_pressure (float | ArrayLike | FunctionGenerator | None)
- class letalker.OpenLungs(lung_pressure=None)#
Parameters#
- lung_pressure, optional
respiratory driving pressure from lungs (dyn/cm²), by default None to use the default value
lt.constants.PL
- class Results(element: 'Element', n0: 'int', nb_samples: 'int', plung: 'NDArray')#
-
- property ts: NDArray#
time vector
- create_result(runner, *extra_items, n0=0)#
Returns simulation result object
- create_runner(n, n0=0, s_in=None, **kwargs)#
instantiate a vocal folds element runner
(overloading abc.Element to account for the aspiration noise sub-element)
Parameters#
- n
number of samples to synthesize
- n0, optional
starting time index, by default 0
- s_in, optional
initial states, by default None
Returns#
simulation runner object
- generate_sim_params(n, n0=0, **_)#
parameters: - lung_pressure: lung pressure
- link(dst)#
set the upstream vocal tract object
Parameters#
- dst
downstream vocal tract
- Parameters:
dst (VocalTract)
- static modify_global_constants(fs=None, c=None, rho=None, mu=None)#
Modify the system constants (use None to keep existing)
Parameters#
- fs
time sampling rate in S/s (samples/second)
- c, optional
speed of sound in cm/s, by default None
- rho, optional
air density in g/cm³ (= kg/mm³), by default None
- mu, optional
air viscosity in dyne-s/cm² (= Pa·s = kg/(m·s)), by default None
- classmethod set_fs(new_fs)#
set class-wide sampling rate.
- Parameters:
new_fs (int | None) – sampling rate in samples/second. If None, it reverts the sampling rate to the default (44.1 kHz).
- static ts(nb_samples, n0=0, sample_edges=False, upsample_factor=0)#
Return time vector in seconds.
Parameters#
- nb_samples
Number of samples
- n0, optional
Starting time sample index, by default 0
- sample_edges, optional
True to return time stamps associated with the edges of the samples, by default False
- upsample_factor, optional
Specify a positive integer to increase the sampling rate of the returned time vector, by default 0
- unlink()#
disconnect the upstream vocal tract object
- Parameters:
lung_pressure (float | ArrayLike | FunctionGenerator | None)
- class letalker.NullLungs(downstream=None)#
Zero-pressure lung model, only reflecting 80% of the backward pressure
- Parameters:
downstream (VocalTract | float)
- create_result(runner, *extra_items, n0=0)#
Returns simulation result object
- create_runner(n, n0=0, s_in=None, **kwargs)#
instantiate a vocal folds element runner
(overloading abc.Element to account for the aspiration noise sub-element)
Parameters#
- n
number of samples to synthesize
- n0, optional
starting time index, by default 0
- s_in, optional
initial states, by default None
Returns#
simulation runner object
- generate_sim_params(n, n0=0)#
parameters: None
- link(dst)#
set the upstream vocal tract object
Parameters#
- dst
downstream vocal tract
- Parameters:
dst (VocalTract)
- static modify_global_constants(fs=None, c=None, rho=None, mu=None)#
Modify the system constants (use None to keep existing)
Parameters#
- fs
time sampling rate in S/s (samples/second)
- c, optional
speed of sound in cm/s, by default None
- rho, optional
air density in g/cm³ (= kg/mm³), by default None
- mu, optional
air viscosity in dyne-s/cm² (= Pa·s = kg/(m·s)), by default None
- classmethod set_fs(new_fs)#
set class-wide sampling rate.
- Parameters:
new_fs (int | None) – sampling rate in samples/second. If None, it reverts the sampling rate to the default (44.1 kHz).
- static ts(nb_samples, n0=0, sample_edges=False, upsample_factor=0)#
Return time vector in seconds.
Parameters#
- nb_samples
Number of samples
- n0, optional
Starting time sample index, by default 0
- sample_edges, optional
True to return time stamps associated with the edges of the samples, by default False
- upsample_factor, optional
Specify a positive integer to increase the sampling rate of the returned time vector, by default 0
- unlink()#
disconnect the upstream vocal tract object
Lips class#
- class letalker.LeTalkerLips(upstream=None)#
Ishizaka-Flanagan
- Parameters:
upstream (VocalTract | float)
Aspiration Noise classes#
- class letalker.LeTalkerAspirationNoise(noise_source=None, REc=None)#
_summary_
Parameters#
- noise_source, optional
_description_, by default None
- REc, optional
_description_, by default None
- Parameters:
noise_source (NoiseGenerator)
REc (float)
- class letalker.KlattAspirationNoise(noise_source=None, alpha=None, REc=None)#
Noise generator in Klatt1990 synthesizer
Parameters#
- noise_source, optional
Aspiration noise source. If float value is given, ColoredNoiseGenerator is used to generate 1st-order lowpass Gaussian noise with -6 dB/oct rolloff with the specified DC level in (cm³/s)/Hz, by default (None) the level is set to 200 (cm³/s)/Hz
- alpha, optional
Noise level loss relative to the default level in (cm³/s)/Hz during sub-critical period (including the closed-phase period), by default None to use 0.5
- REc, optional
Critical Reynolds number to produce the full aspiration noise, by default None
- Parameters:
noise_source (NoiseGenerator | float | dict | None)
alpha (float)
REc (float)
Function Generators#
Standalone Generators#
- class letalker.Constant(level: float | Sequence[float], *, transition_time: float | Sequence[float] | None = None, transition_type: Literal['step', 'linear', 'raised_cos', 'exp_decay', 'exp_decay_rev', 'logistic', 'atan', 'tanh', 'erf'] | Sequence[Literal['step', 'linear', 'raised_cos', 'exp_decay', 'exp_decay_rev', 'logistic', 'atan', 'tanh', 'erf']] = 'raised_cos', transition_time_constant: float | Sequence[float] = 0.002, transition_initial_on: bool = False, **kwargs)#
add a function generator an ability to introduce on/off transition effects
Parameters#
- transition_time, optional
time of the on/off transition or times if multiple transition points, by default None (no taper effect)
- transition_type, optional
transition type or types if multiple transitions with different types, by default ‘raised_cos’
- transition_time_constant, optional
transition step_time constant/duration or constants/durations if multiple steps with different settings, by default 0.002
- transition_initial_on, optional
True to turn off the waveform at the first transition time, by default False
Note: If
transition_typeortransition_time_constantis shorter thantransition_time, their values are cycled.- Parameters:
level (float | NDArray)
- class letalker.StepGenerator(transition_times, levels, *, transition_type='raised_cos', transition_time_constant=0.002, **kwargs)#
stepping function generator
Parameters#
- transition_times
transition times (must be monotonically increasing and has one less item than
levels)- levels
a sequence of the signal levels
- transition_type, optional
transition type or types if multiple steps with different types, by default ‘raised_cos’
- transition_time_constant, optional
transition time constant/duration or constants/durations if multiple steps with different settings, by default 0.002
Note: If
typeortime_constantis shorter thantime, their values are cycled.
- class letalker.LineGenerator(tp: tuple[float, float], xp: tuple[float | NDArray, float | NDArray], *, outside_values: Literal['hold', 'extend'] | None = None, transition_time: float | Sequence[float] | None = None, transition_type: StepTypeLiteral | Sequence[StepTypeLiteral] = 'raised_cos', transition_time_constant: float | Sequence[float] = 0.002, transition_initial_on: bool = False)#
add a function generator an ability to introduce on/off transition effects
Parameters#
- transition_time, optional
time of the on/off transition or times if multiple transition points, by default None (no taper effect)
- transition_type, optional
transition type or types if multiple transitions with different types, by default ‘raised_cos’
- transition_time_constant, optional
transition step_time constant/duration or constants/durations if multiple steps with different settings, by default 0.002
- transition_initial_on, optional
True to turn off the waveform at the first transition time, by default False
Note: If
transition_typeortransition_time_constantis shorter thantransition_time, their values are cycled.
- class letalker.Interpolator(tp_or_fs, xp, **kwargs)#
add a function generator an ability to introduce on/off transition effects
Parameters#
- transition_time, optional
time of the on/off transition or times if multiple transition points, by default None (no taper effect)
- transition_type, optional
transition type or types if multiple transitions with different types, by default ‘raised_cos’
- transition_time_constant, optional
transition step_time constant/duration or constants/durations if multiple steps with different settings, by default 0.002
- transition_initial_on, optional
True to turn off the waveform at the first transition time, by default False
Note: If
transition_typeortransition_time_constantis shorter thantransition_time, their values are cycled.- Parameters:
tp_or_fs (ArrayLike | float)
xp (ArrayLike)
- class letalker.PeriodicInterpolator(tp_or_fs, xp, *, closed=True, **kwargs)#
add a function generator an ability to introduce on/off transition effects
Parameters#
- transition_time, optional
time of the on/off transition or times if multiple transition points, by default None (no taper effect)
- transition_type, optional
transition type or types if multiple transitions with different types, by default ‘raised_cos’
- transition_time_constant, optional
transition step_time constant/duration or constants/durations if multiple steps with different settings, by default 0.002
- transition_initial_on, optional
True to turn off the waveform at the first transition time, by default False
Note: If
transition_typeortransition_time_constantis shorter thantransition_time, their values are cycled.- Parameters:
tp_or_fs (ArrayLike)
xp (ArrayLike)
closed (bool)
- class letalker.ClampedInterpolator(tp_or_fs, xp, **kwargs)#
add a function generator an ability to introduce on/off transition effects
Parameters#
- transition_time, optional
time of the on/off transition or times if multiple transition points, by default None (no taper effect)
- transition_type, optional
transition type or types if multiple transitions with different types, by default ‘raised_cos’
- transition_time_constant, optional
transition step_time constant/duration or constants/durations if multiple steps with different settings, by default 0.002
- transition_initial_on, optional
True to turn off the waveform at the first transition time, by default False
Note: If
transition_typeortransition_time_constantis shorter thantransition_time, their values are cycled.- Parameters:
tp_or_fs (ArrayLike)
xp (ArrayLike)
- class letalker.FlutterGenerator(fl: float, f: ArrayLike | float | None = None, n: int | None = None, phi0: ArrayLike | Literal['random'] | None = None, *, bias: float | FunctionGenerator = 0.0, transition_time: float | Sequence[float] | None = None, transition_type: Literal['step', 'linear', 'raised_cos', 'exp_decay', 'exp_decay_rev', 'logistic', 'atan', 'tanh', 'erf'] | Sequence[Literal['step', 'linear', 'raised_cos', 'exp_decay', 'exp_decay_rev', 'logistic', 'atan', 'tanh', 'erf']] = 'raised_cos', transition_time_constant: float | Sequence[float] = 0.002, transition_initial_on: bool = False, **kwargs)#
add a function generator an ability to introduce on/off transition effects
Parameters#
- transition_time, optional
time of the on/off transition or times if multiple transition points, by default None (no taper effect)
- transition_type, optional
transition type or types if multiple transitions with different types, by default ‘raised_cos’
- transition_time_constant, optional
transition step_time constant/duration or constants/durations if multiple steps with different settings, by default 0.002
- transition_initial_on, optional
True to turn off the waveform at the first transition time, by default False
Note: If
transition_typeortransition_time_constantis shorter thantransition_time, their values are cycled.
- class letalker.SineGenerator(fo: float | FunctionGenerator, A: float | FunctionGenerator | None = None, phi0: float | Literal['random'] | FunctionGenerator | None = None, *, bias: float | FunctionGenerator | None = None, transition_time: float | Sequence[float] | None = None, transition_type: Literal['step', 'linear', 'raised_cos', 'exp_decay', 'exp_decay_rev', 'logistic', 'atan', 'tanh', 'erf'] | Sequence[Literal['step', 'linear', 'raised_cos', 'exp_decay', 'exp_decay_rev', 'logistic', 'atan', 'tanh', 'erf']] = 'raised_cos', transition_time_constant: float | Sequence[float] = 0.004 / pi, transition_initial_on: bool = False, **kwargs)#
add a function generator an ability to introduce on/off transition effects
Parameters#
- transition_time, optional
time of the on/off transition or times if multiple transition points, by default None (no taper effect)
- transition_type, optional
transition type or types if multiple transitions with different types, by default ‘raised_cos’
- transition_time_constant, optional
transition step_time constant/duration or constants/durations if multiple steps with different settings, by default 0.002
- transition_initial_on, optional
True to turn off the waveform at the first transition time, by default False
Note: If
transition_typeortransition_time_constantis shorter thantransition_time, their values are cycled.- Parameters:
fo (float | FunctionGenerator)
A (float | FunctionGenerator | None)
phi0 (FunctionGenerator)
- class letalker.ModulatedSineGenerator(fo: float | ArrayLike | FunctionGenerator, m_freq: float | ArrayLike | FunctionGenerator, am_extent: float | ArrayLike | FunctionGenerator | None = None, fm_extent: float | ArrayLike | FunctionGenerator | None = None, am_phi0: float | ArrayLike | Literal['random'] | FunctionGenerator | None = None, fm_phi0: float | ArrayLike | Literal['random'] | FunctionGenerator | None = None, A: float | ArrayLike | FunctionGenerator | None = None, phi0: float | ArrayLike | Literal['random'] | None = None, *, bias: float | FunctionGenerator | None = None, transition_time: float | Sequence[float] | None = None, transition_type: Literal['step', 'linear', 'raised_cos', 'exp_decay', 'exp_decay_rev', 'logistic', 'atan', 'tanh', 'erf'] | Sequence[Literal['step', 'linear', 'raised_cos', 'exp_decay', 'exp_decay_rev', 'logistic', 'atan', 'tanh', 'erf']] = 'raised_cos', transition_time_constant: float | Sequence[float] = 0.004 / pi, transition_initial_on: bool = False)#
add a function generator an ability to introduce on/off transition effects
Parameters#
- transition_time, optional
time of the on/off transition or times if multiple transition points, by default None (no taper effect)
- transition_type, optional
transition type or types if multiple transitions with different types, by default ‘raised_cos’
- transition_time_constant, optional
transition step_time constant/duration or constants/durations if multiple steps with different settings, by default 0.002
- transition_initial_on, optional
True to turn off the waveform at the first transition time, by default False
Note: If
transition_typeortransition_time_constantis shorter thantransition_time, their values are cycled.- Parameters:
fo (float | ArrayLike | FunctionGenerator)
m_freq (float | ArrayLike | FunctionGenerator)
am_extent (float | ArrayLike | FunctionGenerator | None)
fm_extent (float | ArrayLike | FunctionGenerator | None)
am_phi0 (float | ArrayLike | Literal['random'] | FunctionGenerator | None)
fm_phi0 (float | ArrayLike | Literal['random'] | FunctionGenerator | None)
A (float | ArrayLike | FunctionGenerator | None)
phi0 (FunctionGenerator)
- class letalker.RosenbergGenerator(fo: float | FunctionGenerator, alpha: float | FunctionGenerator | None = None, *, open_quotient: float | FunctionGenerator | None = None, speed_quotient: float | FunctionGenerator | None = None, phase: float = 0.0, pulse_type: Literal['triangular', 'polynomial', 'trigonometric1', 'trigonometric2', 'trignometric3', 'trapezoidal'] | None = None, bias: float | FunctionGenerator | None = None, transition_time: float | Sequence[float] | None = None, transition_type: Literal['step', 'linear', 'raised_cos', 'exp_decay', 'exp_decay_rev', 'logistic', 'atan', 'tanh', 'erf'] | Sequence[Literal['step', 'linear', 'raised_cos', 'exp_decay', 'exp_decay_rev', 'logistic', 'atan', 'tanh', 'erf']] = 'raised_cos', transition_time_constant: float | Sequence[float] = 0.004 / pi, transition_initial_on: bool = False, **kwargs)#
add a function generator an ability to introduce on/off transition effects
Parameters#
- transition_time, optional
time of the on/off transition or times if multiple transition points, by default None (no taper effect)
- transition_type, optional
transition type or types if multiple transitions with different types, by default ‘raised_cos’
- transition_time_constant, optional
transition step_time constant/duration or constants/durations if multiple steps with different settings, by default 0.002
- transition_initial_on, optional
True to turn off the waveform at the first transition time, by default False
Note: If
transition_typeortransition_time_constantis shorter thantransition_time, their values are cycled.- Parameters:
fo (float | FunctionGenerator)
alpha (float | FunctionGenerator | None)
Function Modifiers#
- class letalker.ProductGenerator(*generators, **kwargs)#
- Parameters:
generators (FunctionGenerator | float)
- class letalker.SumGenerator(*generators, **kwargs)#
- Parameters:
generators (list[FunctionGenerator])
- class letalker.ExponentialGenerator(exponent: FunctionGenerator, *, base: float | None = None, scale: FunctionGenerator | float | None = None, bias: FunctionGenerator | float | None = None, transition_time: float | Sequence[float] | None = None, transition_type: StepTypeLiteral | Sequence[StepTypeLiteral] = 'raised_cos', transition_time_constant: float | Sequence[float] = 0.002, transition_initial_on: bool = False)#
add a function generator an ability to introduce on/off transition effects
Parameters#
- transition_time, optional
time of the on/off transition or times if multiple transition points, by default None (no taper effect)
- transition_type, optional
transition type or types if multiple transitions with different types, by default ‘raised_cos’
- transition_time_constant, optional
transition step_time constant/duration or constants/durations if multiple steps with different settings, by default 0.002
- transition_initial_on, optional
True to turn off the waveform at the first transition time, by default False
Note: If
transition_typeortransition_time_constantis shorter thantransition_time, their values are cycled.- Parameters:
exponent (FunctionGenerator)
- class letalker.LogGenerator(antilog: FunctionGenerator, *, base: float | None = None, scale: FunctionGenerator | float | None = None, bias: FunctionGenerator | float | None = None, transition_time: float | Sequence[float] | None = None, transition_type: StepTypeLiteral | Sequence[StepTypeLiteral] = 'raised_cos', transition_time_constant: float | Sequence[float] = 0.002, transition_initial_on: bool = False)#
add a function generator an ability to introduce on/off transition effects
Parameters#
- transition_time, optional
time of the on/off transition or times if multiple transition points, by default None (no taper effect)
- transition_type, optional
transition type or types if multiple transitions with different types, by default ‘raised_cos’
- transition_time_constant, optional
transition step_time constant/duration or constants/durations if multiple steps with different settings, by default 0.002
- transition_initial_on, optional
True to turn off the waveform at the first transition time, by default False
Note: If
transition_typeortransition_time_constantis shorter thantransition_time, their values are cycled.- Parameters:
antilog (FunctionGenerator)
Random Noise Generators#
- class letalker.WhiteNoiseGenerator(psd_level=None, innovation_distribution='gaussian')#
White noise generator
Parameters#
- psd_level, optional
PSD peak level in 1/Hz (default: 1)
- innovation_distribution, optional
- distribution of innovation process with zero mean and unit variance:
“gaussian” Gaussian (normal) distribution “uniform” Uniform distribution “two_point” Two-point (±1) distribution
- class letalker.ColoredNoiseGenerator(*args, psd_level=None, innovation_distribution='gaussian', **kwargs)#
White noise generator
Parameters#
- psd_level, optional
PSD peak level in 1/Hz (default: 1)
- innovation_distribution, optional
- distribution of innovation process with zero mean and unit variance:
“gaussian” Gaussian (normal) distribution “uniform” Uniform distribution “two_point” Two-point (±1) distribution